SMFS: Memory as a Filesystem
LLM agents typically gain persistent memory through one of two paradigms: a filesystem of past notes the agent reads, writes, and searches with standard tools, or a vector index that returns semantically ranked chunks through a single search call. Each is effective in isolation and limited at scale. Filesystems give agents structural context but degrade as corpora grow beyond what filenames can signpost. Vector indices give semantic reach but return chunks severed from their surrounding context, leaving multi-hop retrieval without an anchor to extend from. Both share a failure mode: every retrieval inflates the agent's context window with intermediate paths, partial reads, and overlapping chunks, degrading reasoning across multi-turn tasks.
We present SMFS, a system that mounts a Supermemory container as a
real, kernel-level filesystem with semantic search wired into the
path operations agents already perform. Inside an SMFS mount,
cat reads a memory, smfs grep runs a
hybrid semantic query scoped to the current path, edits propagate
back to the cloud through a bounded per-path push queue, and
/profile.md exposes generated static and dynamic
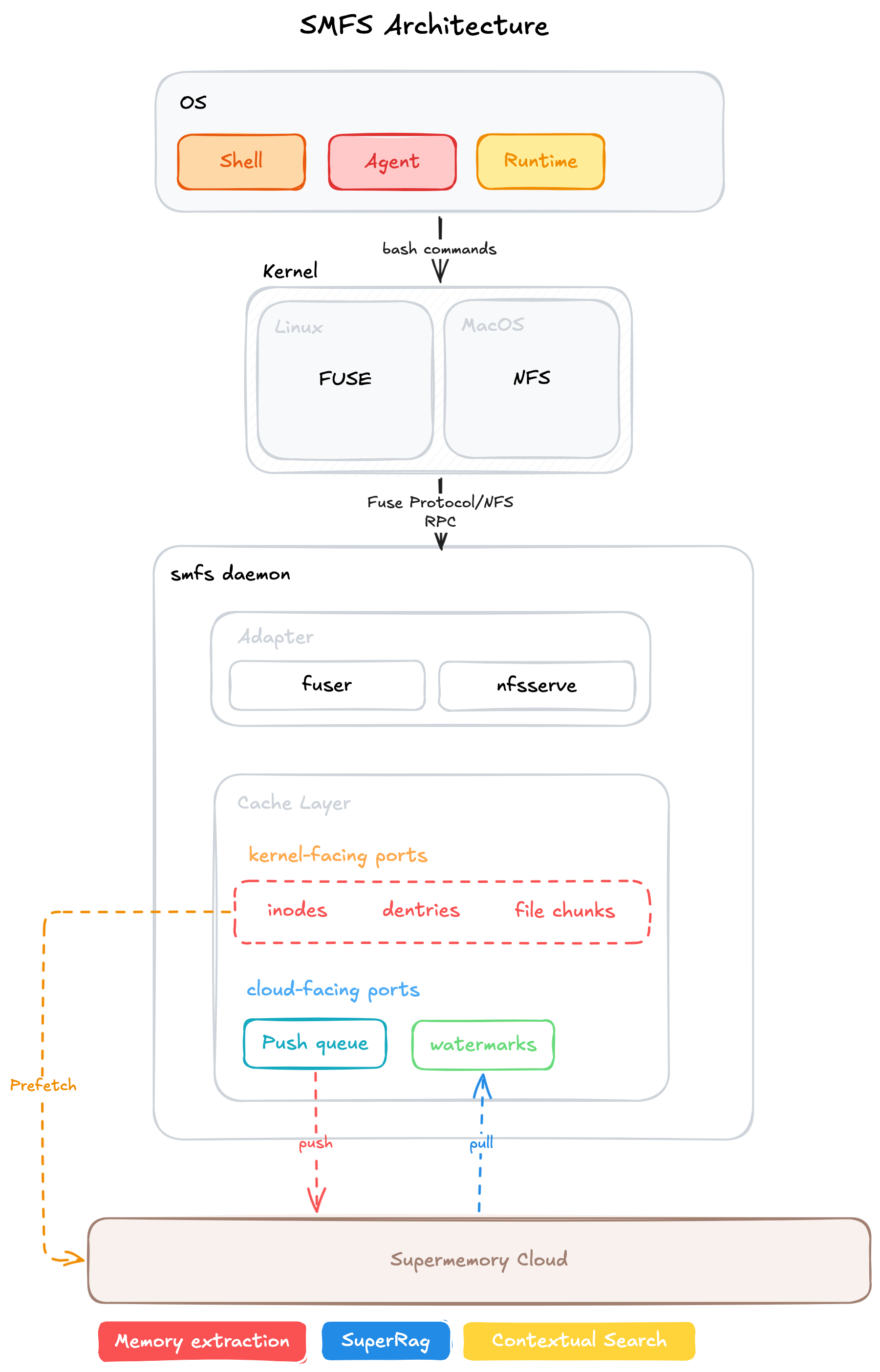
memories as a single filesystem read. A three-layer architecture
(kernel mount, local SQLite cache, cloud) serves filesystem
operations locally while four background loops reconcile remote
state. The same surface ships across runtimes: FUSE on Linux, NFS
on macOS, and a virtual-bash SDK for serverless environments.
Alongside the system, we release xAFS, a
benchmark of 110 audited questions over 13 cross-context corpora
ranging from 5 to ~10,000 files, designed to measure the cost
curve of agentic retrieval at scale. Across two frontier agents
over n=440 trials per condition, SMFS reduces total
tokens consumed by 53.8% and tokens per correct answer by 53.1%
relative to a filesystem-native baseline, at near-parity pass
rate.
Leaderboard
 FS × claude-opus-4.7 [max] SMFS × claude-opus-4.7 [max]
FS × claude-opus-4.7 [max] SMFS × claude-opus-4.7 [max] Cumulative tokens across all 110 xAFS questions, summed per agent-condition.
Per-DP cumulative tokens for claude-opus-4.7, summed across all questions in each DP.
Per-DP cumulative tokens for gpt-5.5, summed across all questions in each DP.
Introduction
Using a filesystem or a vector index in conjunction with an LLM agent is a common paradigm for providing persistent memory beyond the context window. The first treats memory as a directory of past notes the agent reads, writes, and searches with standard tools. The second treats memory as a vector index in the style of retrieval-augmented generation (RAG): a corpus indexed for semantic similarity, queried through a single search call returning a ranked list of chunks. Each is effective in isolation, and each is fundamentally limited.
The filesystem approach is well-suited only to small, organized corpora. When a memory directory contains a few dozen well-named documents, the agent can list it, identify the relevant file by name, and grep for the literal string it wants. As the corpus grows, this assumption breaks. Filenames stop being reliable signposts, hierarchies decay as memories accumulate, and the agent walks an ever-larger tree, opening files speculatively and consuming context at every step. The failure is not that the filesystem cannot answer the question; it is that the agent cannot ask the right question.
The vector-index approach inverts the problem. A single semantic query
can recover content on meaning alone, returning passages from deep
within the corpus that no grep could have located. What
comes back, however, is a ranked list of chunks bounded by a top-K
cutoff: excerpts that arrive without their neighbors, severed from the
surrounding paragraphs and related files that would otherwise let the
agent place them in context. Multi-hop retrieval, in which the next
query depends on context from the previous result, suffers in
particular: the agent has no anchor to extend from.
A common factor compounds both failure modes: the growth of the agent's context window over a multi-turn task. As the agent issues retrievals, its context fills with intermediate results, file paths and partial reads from a filesystem walk, overlapping chunks from a vector query, many of which are tangential or redundant. The bottleneck of agentic memory is therefore not the speed of any single retrieval. It is the number of retrievals the agent must issue before it has gathered enough context to answer. We measure this directly: across the 5- to 9,988-file range of our benchmark, per-question token cost grows ~7× for a filesystem-only agent against ~4× for SMFS.
SMFS is built on top of Supermemory, a context cloud for agents that turns raw user and organizational data into persistent, queryable memory. Supermemory ingests documents into typed containers, extracts text from PDFs, web pages, images, audio, video, and raw files, and indexes the result with hybrid lexical-and-semantic retrieval, reranking, and structured context. Unlike a conventional vector database that stores and returns isolated chunks, Supermemory is powered by a custom user-understanding model and a graph engine in which memories, documents, entities, profiles, and retrieval results live in one ontology-aware structure. The graph supports update, merge, contradiction handling, inference, forgetting, and low-latency traversal, so memory can evolve across sessions rather than being appended as disconnected embeddings. A pipeline over the ingested content distills two kinds of generated memories per container: static memories (durable facts the agent should keep across sessions) and dynamic memories (newer contextual signals that matter for the current work), summarized together into a single profile. Every Supermemory primitive, document, container, memory, profile, graph traversal, and search, gets a direct filesystem surface in the mount, which is what the rest of this paper describes.
A recent line of work converges on the same observation from the
runtime side: agents already operate through files and shells, so
memory should look like a filesystem too.
Files-Are-All-You-Need argues that file-like abstractions
give agentic systems a composable and auditable control surface;
Vercel's bash-tool and just-bash ship that
idea as a runtime, keeping context in a filesystem and exposing
bash-like commands such as find, cat, and
grep so the model can retrieve smaller slices instead of
loading everything into the prompt. Turso's AgentFS is the closest
systems reference: an agent runtime stored in SQLite and exposed as a
POSIX-like filesystem with key-value state and tool-call history, so
agent state is portable, queryable, and auditable. SMFS shares the
file-shaped surface; what differs is the object on the other side of
the mount: a remote memory backend with extraction, embedding, hybrid
search, and a generated profile, rather than a local agent runtime.
We present SMFS, a system that exposes a Supermemory cloud container as a real, mountable filesystem with semantic search wired into the path operations the agent already performs, collapsing the retrieval count by letting a single search land directly on a path the agent can read. We also release xAFS, an open benchmark designed to make the cost curve measurable.
Dataset
No public dataset, to our knowledge, measures interactive retrieval cost over a cross-context corpus as it scales. Conversational long-term memory benchmarks (LongMemEval) measure recall across chat sessions, not file-system retrieval. Long-context comprehension benchmarks (NoLiMa, HELMET, InfiniteBench) concatenate content into a single window and measure in-window QA; no retrieval is performed. Office-workflow benchmarks (OfficeBench, TheAgentCompany) score workflow correctness on fixed-size corpora. Code-generation benchmarks like SWE-bench operate on source repositories rather than the cross-context mix of email, transcripts, and notes that a real working folder contains.
To fill this gap, we built and release xAFS: a benchmark of 110 audited questions over 13 cross-context personal-corpus snapshots ranging from 5 to ~9,988 files, totaling 837 MB across 19,169 files. Each snapshot is a self-contained synthetic persona spanning a distinct domain (management consulting, clinical longitudinal records, civil litigation, open-source maintainership, investigative journalism, executive archive at Series C scale, and others) with a realistic file-type mix: email threads, Slack-style exports, meeting transcripts, structured memos, journal entries, and transcribed audio and image content.
Corpus sizes are logarithmically spaced (5, 10, 20, 30, 50, 100, 200,
299, 480, 991, 1,998, 4,998, 9,988 files), making the dataset suitable
for plotting retrieval cost as a function of scale. Questions cover
three retrieval-shape families:
single_hop (34 questions; answer derivable from a
single file), multi_hop (51 questions; answer combines
two or more files), and format_spanning (26 questions;
answer requires reading at least two distinct content formats). Each
question carries a stable id, a family, a
prompt, a list of gold_file_ids pointing to
files in which the answer is derivable, and a canonical
gold_answer. Every gold answer is independently audited
against the visible corpus; the scenario specifications and fact
registries used during generation are excluded from the public release,
so the file corpus is the only source of ground truth available to an
evaluating agent.
The dataset is released at huggingface.co/datasets/supermemory/xAFS. Full benchmark design, the seven-stage generation pipeline, audit methodology, and known limitations are documented in a separate technical report.
Architecture
SMFS is built around a simple constraint: agent memory should behave like files without giving up the retrieval behavior of a semantic index. A normal filesystem gives agents stable paths, incremental reads, edits, renames, and familiar tools. A memory backend gives them extraction, embedding, profile generation, and search over meaning. The architecture exists to keep those two views coherent while neither side runs at the same speed.
We call this property path-coherent memory. A path in the mount is not only a local filename; it is also the handle used for cloud storage, sync reconciliation, search scoping, transcription placement, and agent guidance. This makes the path the shared unit of coordination across the kernel, the local cache, and Supermemory's API. The rest of the system is designed to preserve that invariant under ordinary filesystem behavior: editors that save through temp-file renames, kernels that split writes into multiple flushes, agents that search before they read, and a backend that accepts a file before it has finished extraction and indexing.
Filesystem Semantics First
The core implementation is not organized around API calls. It starts with a virtual filesystem interface: lookup, read, write, rename, unlink, readdir, stat, symlink, and related POSIX-shaped operations. Both mount backends call into this same interface, and the SQLite-backed implementation satisfies it. This separation matters because the hard contract is not "can we upload a document?" but "can this directory behave enough like a real filesystem that existing tools and agents stop treating it as special?"
SMFS keeps kernel-facing concerns at the edge. On Linux, the mount is served through FUSE. On macOS, where shipping a FUSE filesystem would require macFUSE, SMFS instead runs an NFSv3 server on localhost and asks the native operating-system NFS client to mount it. The two paths differ at the protocol boundary, but converge immediately into the same filesystem trait. The cloud client never needs to know whether a read came from FUSE, NFS, an editor, or an agent.
The Cache Is The Local Truth
Every read served to the kernel comes from a local SQLite cache. This is a deliberate choice. If ordinary file reads depended directly on the network, the mount would inherit the latency and partial-failure behavior of the backend. Instead, the cache stores inodes, directory entries, file chunks, symlink targets, remote document IDs, sync watermarks, and the persistent push queue. SQLite runs in WAL mode with a single serialized connection per mount, giving the daemon a small, durable state machine rather than a pile of in-memory bookkeeping.
The cache is passive: it does not call the API and it does not own background work. Filesystem operations mutate local state; the sync engine observes that state and reconciles it with Supermemory. A write completes once bytes are committed locally, while upload, extraction, embedding, indexing, retry, and conflict handling proceed outside the kernel path.
Two timestamps make this possible. dirty_since records
when an inode was last changed locally, so a pull cannot overwrite an
edit that has not finished pushing. mirrored_updated_at
records the remote version the cache believes it has mirrored, so the
pull side can skip work that has already been incorporated. Together
they let SMFS distinguish three states that otherwise look similar:
local data newer than cloud data, cloud data newer than local data, and
local data already synchronized.
The Daemon Owns the Boundary
A mounted container is owned by a long-running daemon. The CLI resolves credentials, chooses the platform backend, starts or foregrounds the daemon, and communicates with it through a small Unix-socket IPC protocol. Each mount has its own cache scoped by organization and container tag, plus a pid file, socket, and log file under the platform cache directory.
On startup, the daemon validates the session, opens or creates the
cache, warms /profile.md, performs the initial pull,
starts the sync loops, mounts the filesystem, and writes a small marker
file near the mount so commands can rediscover the container tag and
mount path. On shutdown, it gives the push queue time to drain before
releasing the mount. If it cannot drain fully, the queue remains in
SQLite and resumes on the next mount.
The result is a filesystem illusion with explicit boundaries. The kernel sees a normal directory. The agent sees files and grep. The backend sees documents, filepaths, memory extraction, profile generation, and hybrid search. The daemon's job is to keep those views close enough that each side can use its native interface without learning the others.
Bidirectional Sync
Bidirectional sync in SMFS starts from an uneven contract. To the operating system, the mount has to behave like a local filesystem: writes return, renames take effect, deletes disappear, reads see the local tree immediately. To Supermemory, the same file is a document moving through an asynchronous memory pipeline: upload, extraction, transcription, chunking, embedding, indexing, and final search visibility.
The SQLite cache is the source of truth for the mounted tree. Supermemory is the shared remote state that the cache converges with. This is eventual consistency in filesystem form: local paths stay coherent now, while cloud memory catches up through bounded background work. The work is decomposed into four background loops.
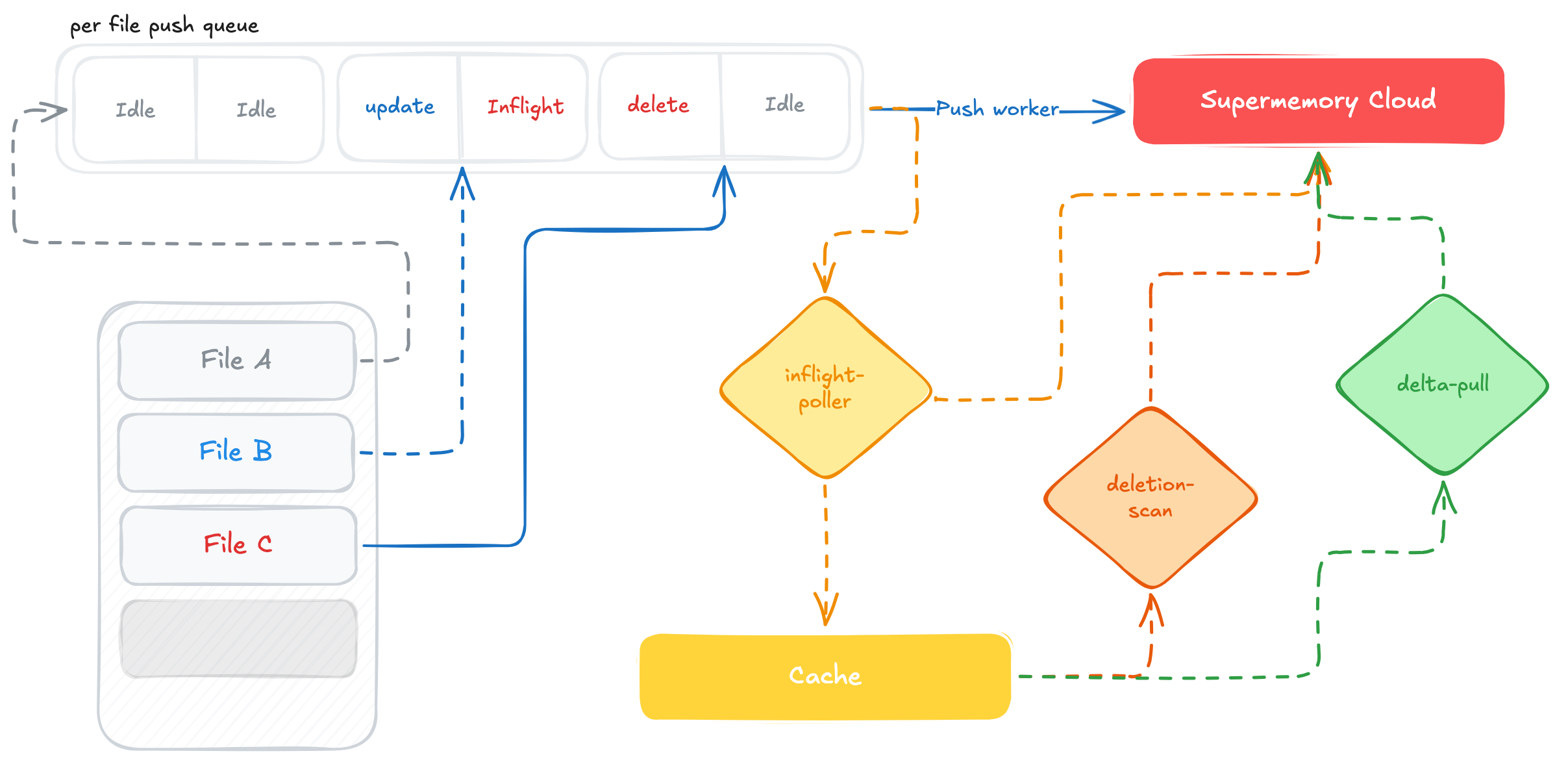
The Write Path: Local Commits and the Push Queue
A local write is committed to the cache before it is sent to the cloud.
SqliteFile::write splits bytes into chunks, updates the
inode size and timestamps, and marks the inode with
dirty_since. From the kernel's point of view, the write
has completed against a normal file. The dirty marker tells the pull
reconciler that this inode has local work which has not safely become
remote state yet; a later remote document should not overwrite it.
On flush, SMFS converts the cached mutation into cloud-facing intent.
The operation becomes a push_queue row: create, update,
upload binary, rename, or delete. The filesystem path is the queue key,
so the queue preserves the same unit of identity the user and agent
see in the mount.
The push queue is persistent, path-scoped, and latest-wins. Each path has two effective slots, one main slot that may be inflight, and one pending slot for the newest change that arrives while the first request is still being processed. If a file is saved repeatedly before the worker claims it, only the latest version remains. This bounds write amplification per file: a burst of saves becomes at most one active request and one remembered follow-up, while different files can still move in parallel.
The push worker wakes on notification, falls back to a short poll,
claims eligible queue rows by setting
inflight_started_at, and sends the corresponding request.
Failures stay local to the row: transient failures clear the inflight
marker, increment attempt, and delay the next claim with
backoff. A successful push clears dirty_since, records
remote identity, and updates mirror state. For updates and renames,
SMFS waits for the previous server-side processing step to finish
before sending the next mutation to the same remote document.
Processing State
Supermemory can accept a document before it is finished becoming memory. The mounted file may already exist locally, while the remote document is still extracting, transcribing, embedding, or indexing. SMFS keeps that intermediate state visible in the cache instead of making the original filesystem call wait for it.
The inflight poller looks at local inodes whose
fs_remote.last_status has not reached done,
then checks the remote processing set in bulk. This matters when many
files are uploaded together: the daemon does not create one polling loop
per file. It asks once, compares the returned processing IDs against
the locally tracked IDs, and only fetches final document state when a
document leaves processing.
When processing completes, SMFS records
mirrored_updated_at and last_status.
The Read Path: Delta Pull and Deletion Scan
The delta-pull loop is the return path. It lists Supermemory documents
ordered by updatedAt descending and stops at the last
watermark. Each newer document is handed to reconcile_one,
which maps the remote document back into the mounted path tree.
Reconciliation is careful about file type and local dirtiness: if the
inode is dirty and the local write is newer than the remote update, the
pull skips it. If the remote document is still processing, SMFS defers
materializing partial content. If the document is done, text-like files
can rewrite local chunks, while binary and media files keep their raw
identity and expose derived text or transcription surfaces separately.
The watermark advances only after the batch has been considered.
Updates have timestamps; deletions are absence. A document removed from
Supermemory does not appear as a newer document in the normal delta
stream, so a separate deletion-scan loop builds the current remote ID
set and compares it with local fs_remote rows. If a known
remote document is gone, SMFS applies the local deletion as long as the
inode is not carrying unsynced local work.
Cross-Mount Convergence
The same Supermemory container can be mounted in more than one sandbox. Each mount has its own SQLite cache, push queue, and four sync loops. The shared state is the container.
If Mount A edits a file, the change first becomes local cache state in A, then a queued push, then a Supermemory document update. Mount B later sees that update through delta pull and reconciles it into its own cache. Local work is accepted immediately, remote memory becomes the convergence point, and dirty local files keep their queued work protected until their own push completes.
File Types and Transcriptions
Agents already know how to search and read text files. SMFS extends that workflow to PDFs, images, audio, video, and webpages by keeping the original file at its path and materializing extracted text as a derived sibling next to it:
research-paper.pdf
research-paper.pdf.pdf-transcription.md
meeting.mp3
meeting.mp3.audio-transcription.md
diagram.png
diagram.png.image-transcription.mdThis convention is deliberately filesystem-shaped. The PDF remains a PDF. The audio file remains audio. The extracted language appears beside it, with a predictable suffix. An agent can search the container semantically, then read the sibling markdown file for the surrounding text instead of loading the original binary into context or choosing a parser itself.
Sibling Lifecycle
A transcription sibling is derived from its source file. It is not treated as a separate user-authored document.
When the source is renamed, the sibling is renamed with it. When the source is deleted, the sibling is removed with it. When Supermemory produces newer extracted text, SMFS rewrites the sibling in place. The source object and its readable surface stay together as the directory changes.
This also gives processing failures a visible filesystem shape. If extraction fails, SMFS places an error sibling next to the source file, so the mount shows why the readable surface is missing instead of hiding that state in daemon logs. The model avoids a common ambiguity in memory filesystems, whether a file path names the original artifact or the processed memory produced from it. In SMFS, the source path remains canonical.
Search Across Types
The sibling model matters because agents search before they read. A semantic search can match content inside a PDF, image, audio recording, video, or webpage because Supermemory indexed the extracted content. SMFS then exposes that same content locally as markdown.
Search finds the relevant source path. The agent reads the sibling file when it needs the extracted text. The user still sees an ordinary directory, but the directory now contains the surfaces an agent needs to work across mixed file types.
Profile and Memory Scope
SMFS gives generated memory a stable file path: /profile.md.
The file appears at the root of every mounted container, including an
otherwise empty mount. It is virtual, read-only, and generated from
Supermemory's profile endpoint. Instead of asking the agent to learn a
profile tool, SMFS puts the profile where the agent already looks: a
file it can open.
The rendered file has a fixed markdown shape:
# Memory Profile
# This file is auto-generated from
# your memories. It is not editable.
# To update, modify the source files
# that contain this information.
## Core Knowledge
- ...
## Recent Context
- ... Core Knowledge comes from static memories: durable facts
that should remain useful across sessions. Recent Context
comes from dynamic memories: newer signals that may matter for the
current work. Writes to /profile.md are rejected by the
mount because the profile is a view over memories, not the source of
truth; to change what appears, the user or agent changes the source
files that generate memories.
Virtual Profile
The Rust mount handles /profile.md outside the normal
cache path. It assigns the file a fixed virtual inode, warms it from
the profile endpoint when the daemon starts, and serves reads from an
in-memory markdown rendering. Root directory reads include
profile.md even when the local cache has no user files.
Profile memory is not hidden behind an API call and it is not mixed
into the writable document tree, it is a stable read surface at the top
of the mount: quick to inspect, safe from accidental edits, and
available before the agent has decided what to search.
Memory Scope
The profile is generated from memories, and SMFS lets the container
decide which filesystem paths produce those memories. On the server,
filesystem-ingested documents are classified by path. The default memory
paths are /memory/, /user/,
/memory.md, and /user.md; a trailing slash
means recursive directory, a path without it is an exact file match.
A mount can override the container's memory paths with
smfs mount <tag> --memory-paths "/notes/,/journal.md",
and passing an empty value disables memory generation for
filesystem-ingested documents. Matching paths run through the memory
pipeline that creates static and dynamic memories. Other
filesystem-ingested documents can still be stored and retrieved as
documents, but they do not feed the profile memory view.
Semantic Search
Agents do not need a new habit to search memory. They already reach for
grep. SMFS keeps that interface and changes the matching
function underneath it. Inside a mounted container,
smfs grep "oauth refresh failure" work/ becomes a
semantic search over the container, scoped to the work/
subtree. The query is still a string. The scope is still a path. The
result still looks like file output.
The difference is what can match. A result may come from a generated memory, a markdown note, a source chunk, or extracted text from a PDF, image, audio file, video, or webpage. SMFS asks Supermemory for a hybrid ranked result set, then renders those hits back into the line-oriented shape agents already know how to follow.
work/debug-notes.md:42-45: refresh
token failed after deploy ...
research-paper.pdf:118-122: the
benchmark failed after token
rotation ...This is the core trade: retrieval becomes semantic, but the interface stays filesystem-shaped. The agent can search by meaning, open the path, inspect the surrounding file, and continue without learning a separate retrieval schema.
Grep as Retrieval
The mounted path gives search a natural scope. A query without a path searches the container. A query with a directory searches that subtree. A query with a file path narrows to that file. SMFS normalizes the path relative to the mount root and uses it as the retrieval boundary.
Literal grep remains literal, the agent reaches for the
system tool when it wants a byte-level match, and reaches for
smfs grep when it wants a semantic one. Both modes stay
available: natural-language lookup for memory retrieval, byte-level
matching for exact inspection.
Returning to Files
Semantic search is only useful if the result can return to the filesystem. For chunk results, SMFS tries to recover a local line range by finding the returned excerpt in the local file. If the verbatim match fails, it retries with whitespace-normalized text so reflowed passages can still resolve to useful lines.
For non-text files, this uses the sibling surfaces from
Section 5. A match inside
research-paper.pdf can be resolved against
research-paper.pdf.pdf-transcription.md; a match inside
an audio recording can resolve against its transcript.
Generated memories are different. They are facts produced by the memory pipeline, not necessarily spans copied from a file. SMFS still prints them in the same result stream, attached to a path when the backend can attribute one. The agent sees compact memory and supporting chunks together, ranked by relevance, instead of doing one search for the fact and another for evidence.
Evaluation
Protocol
The headline metric is tokens per correct answer. An
agent's per-question cost is the total of input and output tokens
consumed across all turns during which it answers the question,
including tool-call payloads. Pass and fail are decided by an LLM judge
(Gemini 2.5 Pro at temperature 0) scoring
(question, gold_answer, candidate_answer) triples for
semantic equivalence with paraphrase and format tolerance. Pass rate,
mean tool calls per question, and mean wall-clock per question are
reported as supplementary metrics.
The agent harness is held constant across two retrieval surfaces:
- fs-only: bash with
grep,find,catover the persona's localdata/directory. The baseline contemporary agentic setup. - smfs: the persona's corpus ingested into a
Supermemory container and exposed through an SMFS mount; the agent
has access to
smfs grep(semantic) in addition to the standard shell.
For each (surface, dp) pair we record per-question tokens, tool-call counts, wall-clock time, and judge verdict. The retrieval-cost curve plotted at corpus size n aggregates over the persona at that size and across all three question families. We run two frontier agent harnesses, Anthropic Claude Code and OpenAI Codex CLI, twice over all 110 questions across all 13 corpora, yielding n=440 trials per condition.
Tool Selection and the Path-Scoped Hint
A key design choice in the SMFS condition is that the agent retains
both matching functions. Plain grep stays
literal; smfs grep performs hybrid semantic retrieval. The
agent must choose between them per query.
Plain grep is universally known by frontier LLMs from
pre-training. smfs grep is not. There is no kernel-level
mechanism that would make the agent discover a new shell command on
its own, and bypassing the shell (e.g., aliasing all
grep calls to semantic) would silently break
literal-string lookups the agent legitimately needs. The minimum viable
mechanism is a single path-scoped hint written into
CLAUDE.md / AGENTS.md in the workspace
directory, the file Claude Code and Codex already read on startup,
describing the existence and shape of smfs grep and
recommending it for semantic queries. The hint and its rationale are
documented in the released eval harness
(eval/conditions/smfs.ts).
We emphasize that the hint is not a thumb on the scale. Both
conditions ship the same base prompt ("Your memory is in
agent_memory/. The answer is in
agent_memory/. Search until you find it."); the SMFS hint
adds only the tool-existence and tool-shape information necessary for
the agent to be able to use smfs grep at all. Withholding
it would not measure "SMFS without an advantage", it would measure
"SMFS with one of its tools hidden from the model." The fs-only
baseline has nothing analogous to hide.
Results
Table 1. Aggregate results, averaged across both agents and all 13 corpora (n=440 per condition). Δ is SMFS relative to fs-only.
| Metric | fs-only | smfs | Δ |
|---|---|---|---|
| Total tokens (M) | 156 | 72 | -53.8% |
| Tokens / correct (×10³) | 766 | 359 | -53.1% |
| Pass rate (%) | 92.7 | 91.4 | -1.4pp |
| Tool calls / question | 10.2 | 6.7 | -33.8% |
Table 2. Per-agent breakdown. Both agents drop tokens and tool calls under SMFS; Claude is at pass-rate parity (slightly positive), while Codex absorbs a small pass-rate hit but still wins on tokens.
| Agent | Metric | fs-only | smfs | Δ |
|---|---|---|---|---|
| Claude | Total tokens (M) | 72 | 24 | -66% |
| Pass rate (%) | 90.0 | 90.9 | +0.9pp | |
| Tool calls / question | 7.8 | 3.1 | -60% | |
| Codex | Total tokens (M) | 84 | 48 | -43% |
| Pass rate (%) | 95.5 | 91.8 | -3.6pp | |
| Tool calls / question | 12.5 | 10.3 | -17% |
Table 3. Per-question results by corpus size. SMFS reduces tokens at every size; at 9,988 files, SMFS pass rate also exceeds fs-only (81% vs 69%).
| Files | fs tok/q | smfs tok/q | fs pass | smfs pass |
|---|---|---|---|---|
| 5 | 232k | 146k | 100% | 100% |
| 10 | 329k | 145k | 94% | 94% |
| 20 | 299k | 174k | 100% | 100% |
| 30 | 312k | 188k | 100% | 100% |
| 50 | 379k | 185k | 94% | 89% |
| 100 | 258k | 170k | 100% | 100% |
| 200 | 528k | 339k | 100% | 100% |
| 299 | 1.54M | 347k | 94% | 88% |
| 480 | 852k | 571k | 88% | 81% |
| 991 | 1.18M | 698k | 100% | 94% |
| 1,998 | 875k | 307k | 88% | 81% |
| 4,998 | 1.16M | 512k | 75% | 75% |
| 9,988 | 1.59M | 605k | 69% | 81% |
Table 4. Pass-rate trade-off by question family. The aggregate -1.4pp pass-rate dip is concentrated entirely in multi-hop questions; single-hop and format-spanning questions are wins on tokens and pass rate.
| Family | n | token Δ | fs pass | smfs pass |
|---|---|---|---|---|
| single_hop | 68 | -61% | 92.6% | 94.1% |
| multi_hop | 100 | -45% | 93.0% | 89.0% |
| format_spanning | 52 | -65% | 92.3% | 92.3% |
Across n=440 trials per condition, SMFS reduces token consumption and tokens per correct answer at near-parity pass rate, with the per-agent breakdown showing that Claude captures the largest efficiency gains while slightly improving on pass rate, and Codex also benefits substantially in tokens while taking a small pass-rate hit.
The aggregate efficiency claim is in Table 1: SMFS uses 53.8% fewer total tokens, and produces correct answers for 53.1% fewer tokens each. The per-agent decomposition (Table 2) is the more interesting story. Claude cuts its tool-call count by 60% on SMFS and improves marginally on pass rate, it is the bigger beneficiary on every axis. Codex also reduces its tool-call count under SMFS, by 17%, indicating that semantic-search shortcuts exploration even for the more exploration-heavy of the two agents; it takes a modest pass-rate hit (-3.6pp) and still ends up substantially cheaper per correct answer. Both readings of the story show up in the numbers: SMFS is a context-management win that compounds with Claude's already efficient navigation, and a net-positive backend swap for Codex that also shifts its retrieval habits.
Per-question token cost vs. corpus size
Figure 1 and Table 3 make the scaling story concrete.
Per-question token cost grows roughly 7× across the file-count
range for fs-only (0.23M to 1.59M tok/q) and only ~4× for SMFS
(0.15M to 0.61M); the 299-file corpus is an outlier where fs-only
thrashes (1.54M tok/q against SMFS's 0.35M). The mechanism is what
the architecture would predict: the fs-only baseline's cost grows
steeply with corpus size because the agent issues progressively more
speculative reads (ls, then a handful of
cats, then a grep for a literal that does
not match, then more cats) to navigate an unfamiliar
directory. SMFS's cost grows more slowly because the same
grep habit retrieves semantically without those
speculative reads.
Pass rate is the second axis. As corpus size grows, fs-only degrades from 100% on corpora of 200 files or fewer to 69% at 9,988 files, a 31pp decline; SMFS degrades more gradually to 81%, surpassing fs-only at the largest scale and suggesting that fs-only retrieval begins to fail outright at extreme scale rather than just become expensive. Decomposed by question family (Table 4), the aggregate -1.4pp pass-rate dip is concentrated entirely in multi-hop questions (-4pp); single-hop and format-spanning questions are wins on both tokens and pass rate. Across the full evaluation, fs-only consumed $2,103 in API spend and SMFS $946, a savings of $1,157 (-55.0%).
Limitations
xAFS is synthetic, audited, and released by the authors of the system under evaluation. We address each directly. The dataset is synthetic because a publicly shareable real cross-context corpus at this scale does not exist; voices and event distributions reflect the priors of the generating model. The dataset is audited so that gold answers cannot be the failure mode: every gold has been independently re-verified against the visible corpus, and the audit log ships with the release. Scaling is measured across distinct personas at distinct sizes, which introduces inter-persona variance into cost-curve estimates; family-distribution balance partially compensates, and the curve should be read as typical-case behavior across thirteen domains rather than an exactly controlled scaling experiment. Question design was completed and frozen against the corpus before any retrieval-system measurements were taken, and the construction pipeline does not preferentially target any retrieval surface. On multi-hop questions specifically, SMFS trades roughly four points of pass rate for 45% fewer tokens (Table 4); we attribute this to top-K semantic retrieval occasionally returning a near-neighbor for the second hop rather than the file the chain requires, and leave tightening this trade-off to future work. We nonetheless encourage independent reproduction and welcome counter-examples.
Conclusion
We argued that the bottleneck of agentic memory is not the speed of any
single retrieval but the number of speculative retrievals the agent
issues before it has gathered enough context to answer, and that
filesystem-only and vector-only memory each amplify that count in their
own way. SMFS responds with a path-coherent design: one identifier, the
path in the mount, carries local storage, cloud document identity,
search scope, transcription placement, and generated memory
simultaneously. The kernel sees a normal directory; the agent uses the
same grep habit it already has; the backend keeps doing
extraction, embedding, and profile generation. Filesystem semantics
live at the edge and complete locally; remote convergence happens in
four explicit background loops backed by a persistent SQLite queue.
On xAFS, the first public benchmark designed around the cost curve of agentic retrieval, SMFS reduces total tokens consumed by 53.8% and tokens per correct answer by 53.1% against a filesystem-native baseline at n=440 trials per condition, winning on tokens at every corpus size with the largest absolute reductions at the upper end of the scale. At the largest corpus, SMFS pass rate also exceeds the fs-only baseline, suggesting that fs-only retrieval breaks down qualitatively at extreme scale, not just quantitatively. The aggregate pass-rate trade-off is near-parity (-1.4pp), with Claude slightly improving and Codex taking a modest hit (-3.6pp). We see agent filesystems as an underexplored area of public research, existing comparisons are demo-shaped, and the benchmarks that exist measure adjacent problems, and we release xAFS so that any reader skeptical of these results can rerun the evaluation, swap the judge, construct adversarial questions, or build a parallel dataset. Future work includes more personas at the top of the scale, surgically injected gold chains and trap files, native multimodal content, and languages beyond English.
Cite this work
@techreport{smfs2026,
title = {SMFS: Memory as a Filesystem},
author = {Prasanna AP and Soham Daga and Dhravya Shah},
year = {2026},
month = {May},
institution = {Supermemory},
url = {https://supermemory.ai/research/memory-as-a-filesystem}
}